Table of Contents
Multikonstelační přijímač GNSS
Přijímač by měl být určený ke zpracování signálu a navigaci z aktuálně dostupných družicových navigačních systémů.
Cílem studie vtupního dílu multikonstelačního přijímače GNSS je nalézt odpověď na následující technické problémy:
- Způsob směšování signálu (převedení do digitalizovatelného pásma)
- A/D převod signálu za směšovačem
- Zpracování digitalizovaného signálu, tj. získání korelační funkce
- Výstup digitálních dat a dat z korelátoru pro další zpracování
Jde převážně o zpracování v ustáleném režimu sledování je však nutné vzít v úvahu i nutnost prvního zachycení v prostoru kmitočet/čas.
Zpracování RF signálu
Přijímač předpokládá připravený RF signál zbavený mimo-pásmového rušení a zesílený na úroveň vhodnou ke zpracování bez extrémních technických nároků na šumové a dynamické parametry 1). V řetězci zpracování signálu se dále již ze zadání předpokládá, že každý navigační systém bude obsluhován vlastním procesním řetězcem. Viz následující blokové schéma:
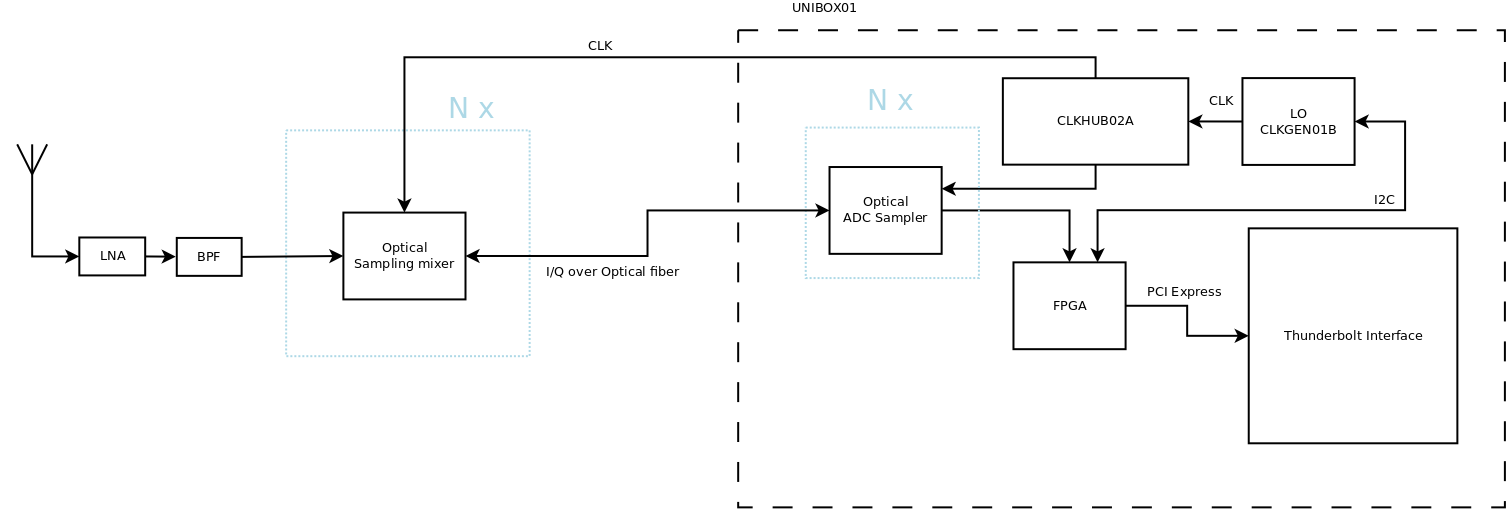
Při průzkumu možných řešení založených na dostupných konstrukcích SDR přijímačů bylo zjištěno, že žádný z nich není vhodný pro přímou realizaci multikonstelačního přijímače. Mezi potenciálně nejvhodnější lze ale zařadit tyto SDR přijímače:
- bladeRF
- Bitshark Express RX
- HackRF
- XRAD-3200
Ve všech případech je ale překážko jejich vysoká cena, která neumožňuje efektivně realizovat vícekanálový přijímač a dále také (kromě HackRF) uzavřený design.
Směšování
Většina navigačních družicových systémů vysílá ve frekvenčním pásmu mezi 1 až 2 GHz, je tedy nutné, aby se směšovací řetězec vypořádal minimálně s tímto frekvenčním rozsahem při zachování vhodných parametrů. Tento problém lze řešit i běžnými klasickými konstrukcemi superhetů. Ovšem vzhledem k tomu, že primárním cílem zpracování RF signálu je získat co nejlepší číslicový popis navigačního signálu, na což tyto konstrukce nebyly primárně vyvíjeny, je žádoucí uvažovat o jiných možnostech směšování do pásma vzorkovatelného dnešními ADC. Navíc zpracování digitalizovaného signálu je vhodné provádět v komplexní obálce.
Z tohoto pohledu se přímo nabízí použití spínaného směšovače, který je výbornou aproximací ideálního směšovače (čtyř-kvadrantové násobičky). Z praktického konstrukčního pohledu je také velmi užitečnou vlastností, že tento typ směšovače principiálně pracuje s digitálním signálem lokálního oscilátoru, který se nejenom velmi snadno generuje ale i snadno přenáší. Navíc na tento signál lze snadno fázové zavěsit další digitální obvody, které tak mohou pracovat synchronně se směšovačem.
Hlavní překážkou realizace přijímače se spínaným směšovačem je nedostupnost dostatečně rychlých elektronických spínačů, které by umožňovaly přímé vzorkování navigačního signálu. Tento problém je ale možné obejít použitím optických spínačů. Například v podobě polovodičových laserových diod, které jsou pro spínání na těchto frekvencích dostatečně rychlé.
Realizace optického spínaného směšovače
Spínaný směšovač lze z optických prvků vytvořit například tak, že klasické elektronické spínače v RF cestě za LNA budou ještě v blízkosti antény nahrazeny za laserové diody ukončené optickými vlákny. Tyto laserové diody budou mít proudový bias napájený RF signálem, který je třeba konvertovat a vzorkovat. Samotné spínání pak bude realizováno přivedením jednoho kvadrantu signálu LO na aktivační vstupy řídící elektroniky laseru. Laserová dioda tak vytvoří impulz jehož energie bude úměrná amplitudě RF signálu za dobu vzorku. A tento signál se bude dále šířit optickým vláknem.
Tento způsob přenosu je znám jako Radio-Frequency-over-Fiber link for large-array radio astronomy applications
Digitalizace
Výše uvedeným způsobem bude signál rozfázován do čtyř optických vláken podobně, jako v klasické konstrukci spínaného směšovače. Na konci těchto optických vláken budou detekční fotodiody s trans-impedančními zesilovači a spínané integrátory, které zintegrují každý celý přijatý impulz. Tento impulz bude ovzorkován ADC a integrátor resetován. Následně může být přijat další impulz, který bude opět ovzorkován a integrátor resetován.
Samotná digitalizace signálu pak může být provedena některým komerčně dostupným ADC. Vzhledem k požadavkům na vzorkování více navigačních RF kanálů paralelně je vhodné zvolit některý obvod určený pro zpracování paralelních signálů. Což jsou například ADC určené pro zpracování vícekanálových ultrazvukových signálů. Takový obvod využívá modul ADCoctoSPI01A.
Tato konstrukce by měla přinášet několik revolučních zlepšení:
- Možnost realizace spínaného směšovače i pro vysoké kmitočty řádově desítky GHz
- Omezení zpětného vyzařování spínacích prvků do antény.
- Snížení nutných požadavků na antialiasing filtr před ADC.
- Možnost dynamického nastavení šířky pásma (závisí na nastavení integrátoru a synchronizaci se vzorky spínaného směšovače).
- Lepší parametry přenosu signálu od antény - Optická vlákna mají cca o řád nižší útlum. Přenos po optických vláknech také nemůže být ovlivněn elektromagnetickým rušením z prostředí ve kterém je veden.
- Nemohou vznikat problémy způsobené vedením více paralelních stínění.
Korelační jednotka
Úkolem korelační jednotky je získávat informace o posuvu navigačních signálů a udržovat jejich sledování. Skládá se ze soustavy korelátorů, generátoru repliky dálko-měrného kódu a regulační smyčky. Jde o zařízení, které obsahuje časově kritické výpočty na velkém objemu dat. Datové toky uvnitř soustavy korelátorů dosahují běžně řádu stovek MB/s neboť je pracováno paralelně s relativně dlouhými úseky signálu. Tyto vlastnosti vzhledem k dostupnému výpočetnímu výkonu dnešních CPU a GPU implikují nutnost hardwarové implementace korelačních algoritmů. Z tohoto důvodu je pak celý tento systém implementovaný v FPGA. Pro testovací účely by v tomto případě bylo možné využít některý ze série modulů S3AN01B
Komunikační rozhraní
Komunikační rozhraní přijímače bude řešit přenos dat mezi výpočetní/řídící jednotkou a FPGA, ve kterém budou implementovány korelátory a základní komunikační protokol pro přenos dat. Na samotný přenos dat jsou kladeny tyto požadavky:
| Proces | Datový objem | Požadavky na přenos |
|---|---|---|
| Obsluha korelátorů | Upload max 8MB/s Download 0,8MB/s | Nízká latence |
| Akvizice | Upload cca 50 MB/s | Časově nekritické |
| Pomocné operace | Upload/Download cca 1kB/s | Časově nekritické |
Na základě těchto požadavků na datové přenosy připadá v úvahu pouze několik dostupných rozhraní. Konktrétní volba komunikačního rozhraní souvisí se způsobem implementace obsluhy korelačňí jednotky. Viz sekce Obsluha korelátoru
USB 3.0
Toto rozhraní je nyní velmi rozšířené a jeho přenosové parametry by byly vyhovující pro uvažovanou aplikaci přijímače. Komplikací ovšem je jeho implementace, neboť má velmi složitý komunikační protokol. A jeho implementace v FPGA je náročná a pravděpodobně by vyžadovala přídavné externí periferie. Tímto způsobem je řešena například konstrukce bladeRF. Na druhou stranu však existuje USB 3.0 device IP core od Xilinx, který deklaruje i možnost použití DMA.
PCI Express
PCI Express je dnes standardní expanzní sběrnice rozšířená ve výpočetním hardwaru včetně průmyslových aplikací. Oproti USB 3.0 má mnoho vylepšení vhodných pro přenos dat v reálném čase. Jedním z nich je například nativní podpora DMA. Další výhodou je na rozdíl od USB 3.0 poměrně nenáročná implementace v FPGA, jelikož většina dnešních FPGA obsahuje HW core blok, který připojení na sběrnici PCIe podporuje. Nevýhodou tohoto rozhraní je jeho problematické vedení na delší vzdálenost. Proto je prakticky omezené pouze na základní desky počítačů a jejich nejbližší okolí.
Thunderbolt
Jde o komunikační rozhraní vycházející z efektivity použití PCI Express jenž rozšiřuje o možnost vedení na delší vzdálenosti mimo základní desku počítače. Toho je dosaženo použitím aktivních metalických, nebo optických kabelů.
Podstatným přínosem tohoto řešení je nezávislost na zvolené výpočetní platformě v době vývoje. Desku s korelátory by bylo proto možné pro účely vývoje propojit se standardním PC pomocí modulu TBPCIE01A, A po zvolení konkrétního výpočetního hardwaru by přijímač byl připojený přímo na jeho PCI Express sběrnici. Tímto způsobem by bylo možné obejít problematický bod volby řídícího počítače. A tím se vyhnout zastarání výpočetního HW před ukončením vývoje.
Řídící počítač
Volba řídící jednotky korelátoru GNSS přijímače je spolu se sofwarovou implementací algoritmů pravděpodobně nejkritičtější součástí projektu. Neboť v současné době v tomto směru dochází k intenzivnímu vývoji na straně výrobců výpočetní techniky. Řídící počítač bude řešit tyto hlavní úkoly:
- Periodickou obsluhu korelátorů (časově kritická záležitost)
- Akvizice přijímače (Výpočetně náročná záležitost)
- Výpočet polohy, dekódování navigační zprávy a příprava dat pro uživatele.
Vzhledem k tomu, že aktuálně je velmi perspektivní architektura ARM, která se však velmi rychle vyvíjí. Tak by bylo vhodné jako výpočetní jednotku pro testovací účely využít standardní PC a pak přejít na ARM po základním otestování algoritmů.
Obsluha korelátorů
Přijímač bude vybaven 50 - 100 korelátory signálu, které budou implementovány v FPGA. Korelátory vyžadují periodickou obsluhu nejdéle jednou za 1 ms vždy na konci posledního bitu PRN kódu. Konec PRN kódu nastává u jednotlivých kanálů v různých časech. Navíc v důsledku Dopplerova jevu dochází k tomu, že perioda kódu se u každé družice mírně liší.
Obsloužení korelátoru znamená přečtení minimálně 10 až 20 32-bitových registrů, výpočet algoritmu a zápis dvou 32 bitových registrů. Algoritmus sice není výpočetně náročný a lze jej implementovat i v pevné desetinné čárce. Ale při obsluze korelátorů nesmí nastávat výpadky. V opačném případě nastane skoková chyba pseudovzdálenosti, naruší se synchronizace navigační zprávy a celého obslužného programu. Opravou je pak provedení opětovného nastavení kanálu, nová akvizice a synchronizace dálkoměrného kódu.
Protože obsluha korelátoru je pak časově náročným problémem existují dva možné přístupy k jeho řešení.
Obsluha korelátoru výpočetní jednotkou umístěnou v FPGA
Pro obsluhu korelátorů, které musí být za současných technických možností nutně hardwarově implementovány se nabízí jejich obsluha přímo v FPGA.
Výhody tohoto přístupu:
- Menší nároky na přenosovou kapacitu a latenci datové linky mezi FPGA a nadřazeným výpočetním systémem.
- Větší efektivita algoritmů a menší latence obsluhy korelátorů.
Tento přístup využívá například konstrukce Homemade GPS Receiver.
Nevýhody tohoto řešení:
- Problematická možnost aktualizace a úpravy algoritmů obsluhy. V podstatě nemožnost dynamické adaptace algoritmů.
- Nutnost specifické komplikované konstrukce výpočetní jednotky pro každý navigační systém zvlášť.
- Problematická realizace konstrukce výpočetní jednotky. (Nejsou dostupné vhodné vývojové nástroje)
Většinu nevýhod tohoto přístupu by sice bylo možné eliminovat použitím FPGA s integrovaným MCU architektury ARM. Avšak tyto hradlová pole jsou dostupná pouze v nepřijatelných cenových relacích řádu stovek USD.
Obsluha korelátoru vnější výpočetní jednotkou
Obsluha korelátorů implementovaných v FPGA může být také realizována vnější výpočetní jednotkou. Která bude dynamicky provázána se stavy korelátorů v FPGA, toto je umožněno například komunikačním rozhraním s možností použití DMA. V takovém případě pak nadřazená výpočetní jednotka periodicky kontroluje stav všech korelátorů pomocí obrazu ve vlastní paměti. A na základě těchto stavů řeší jejich obsluhu.
Výhody řešení:
- Snadná možnost dynamické aktualizace metody obsluhy korelátorů změnou programu v nadřazené výpočetní jednotce.
- Implementační obtížnost je podobná pro všechny navigační systémy.
- Systém lze téměř libovolně škálovat, protože jeho rozsah je limitován pouze přenosovou kapacitou použitého rozhraní a výpočetním výkonem nadřazené řídící jednotky.
Nevýhody řešení:
- Nutnost dobře implementovaného driveru a řadiče DMA.
- Nutnost vysokorychlostní datové komunikační linky mezi FPGA a nadřazenou výpočetní jednotkou.
Akvizice přijímače
V tomto režimu je potřeba přenést do výpočetní jednotky vzorky signálu z jednoho RF kanálu o časovém úseku 10 až 100 ms a vzorky následně zpracovat. Vzorkovací rychlost se bude pohybovat mezi 20 až 25 Msps. Bude vzorkována komplexní obálka, takže jeden vzorek bude reprezentován dvěma slovy, požadovaný datový objem přenosu tedy je přibližně 40 až 50 MB/s. Celkový objem přenášených dat pro jeden výpočet je 500 kB až 5 MB.
Základem zpracování naměřeného úseku signálu v počítači je výpočet vícerozměrné korelace. Tuto korelaci lze s výhodou počítat pomocí FFT. Pro většinu GNSS signálů se signál rozdělí do úseků o době trvání 1 ms, signál se převede do spektra, vynásobí spektrem repliky a pak zase zpátky do časové oblasti, jednotlivé úseky se přitom nekoherentně sčítají. Tento algoritmus lze dnes efektivně počítat v GPU pomocí OpenCL
V režimu akvizice je kritický pouze přenos dat z FPGA do počítače, vlastní výpočet pak může běžet asynchronně.
Pomocné procesy na řídící jednotce
Výpočet polohy, dekódování navigační zprávy a řízení přijímače jsou časově nekritické činnosti. Provádí se podle požadované hustoty navigačních dat, výpočty je ale potřeba provádět v plovoucí desetinné čárce. Jsou vyžadovány maticové operace. Pro uložení navigační zprávy od 100 družic je třeba cca. 1 MB paměti. Algoritmy řízení přijímače budou komunikovat s FPGA. Komunikace bude časově nekritická. Přenášený objem dat bude kolem 1 kB za sekundu v obou směrech.
Z uvedených požadavků na výpočetní výkon a komunikační rozhraní vychází koncepce FPGA s DMA přenosem do paměti výpočetní jednotky jako nejlepší řešení. Navíc v připadě použití operačního systému Linux na víceprocesorovém systému tak, aby jeden procesor (jádro) obsluhoval jen hardware, tak by byl zároveň odstraněn problém s latencí interruptů (jinak lze řešit i bez přerušení jen semafory v operační paměti). Zbývající jádra by pak mohla být použita na časově nekritické výpočty.
Jako výpočetní jednotka by v takovém případě mohl být použit některý jednodeskový počítač vybavený více-jádrovým procesorem ARM a GPU jednotkou podporující OpenCL pro výpočet akvizice.
Programové zpracování
Vytvoření softwaru je nejproblematičtější částí projektu. Jelikož softwarové algoritmy jsou hlavní částí probrému.
Ideálním řešením obsluhy přerušení by bylo přesměrování intrerruptu od korelátorů pouze na jedno jádro procesoru (známé jako afinita procesoru).
- Latence přerušení ve stovkách mikrosekund je obtížně zajistitelná běžnými prostředky OS
- Použití jiného OS než Linuxu může být problém v ceně a obtížnosti SW realizace (licence, nástroje, know-how).
Na dnešním HW FPGA je k dispozici PCIe Gen 2, tedy cca 500MB/s full-duplex. To znamená, že přenos 5MB bude trvat přibližně 1ms (reálně počítejme spíš 2-3ms). Za stejnou cenu můžeme mít i PCIe Gen2 x4.
Latence čtení přes PCIe (čas od požadavku do obdržených dat) bývá řádově stovky nanosekund (a hodně závisí na mainboardu a na tom, co počátač dělá). Zápisy jsou příznivější, protože se na ně nečeká. Tedy data ze zařízení je lepší přenášet DMA do paměti PC, zápis z PC do FPGA je možné přímo, ale je to nevýhodné pokud to je víc, než několik slov. Procesor prakticky negeneruje burst přenosy.
Real-time operační systémy
Výsledky studie
Studie se zabývala nalezením řešení na několik technických problémů, které jsou ale vzájemně provázány tak, že pravděpodobně nebude možné nalézt konečné řešení v jednom kroku. Proto by bylo vhodné zvolit postupnou aproximaci, kdy bude nejdříve realizován testovací přípravek, který bude sloužit primárně k ověření správné implementace algoritmů, které jsou realizačně nejnáročnější částí celého problému.
Testovací přípravek
Tento testovací přípravek by se měl zaměřit nejdříve pouze na jeden navigační systém, neboť náročnost problému se se vzrůstajícím počtem použitých navigačních systémů škáluje nelineárně, v důsledku toho, že každý navigační systém potřebuje jiný algoritmus obsluhy korelační jednotky.
Pro realizaci testovacího přípravku by bylo vhodné využít již existující řešení kombinace FPGA a přijímače a rozhraní k výpočetní jednotce. Přijímač v této fázi může být řešen libovolným způsobem, protože v této fázi jde primárně o vyřešení algoritmických problémů.
Vhodným existujícím přijímačem by v takovém případě byl přímo WitchNavigator, který má parametry vyhovující i pro případnou implementaci obsluhy korelátoru výpočetní jednotkou umístěnou v FPGA. Pro přenos dat WitchNavigator používá rozhraní PCI Express, které je svými parametry dostatečné pro implementaci obou přístupů implementace obsluhy korelátorů, navíc nemá problém s přenosem dat v režimu akvizice.
Jako nadřazenou výpočetní jednotku by bylo rozumné pro testovací účely použít standardní PC Ix86 platformu s operačním systémem Linux, nebo unix. Důvodem k tomuto postupu je skutečnost, že PC poskytuje aktuálně největší dostupnou výpočetní kapacitu pro signálové výpočty.
Během vývoje softwaru na testovacím přípravku by měla být řešena hardwarová realizace směšování a digitalizace vstupního signálu.
Realizace funkčního demonstrátoru
Rozšířením testovacího přípravku na další navigační systémy a na více kanálů by došlo k realizaci funkčního demonstrátoru zařízení. Toto rozšíření může být provedeno jednak přidáním redukčních karet na ExpressCard pro Witchav do standardního PCIe slotu. A nebo použitím rozhraní Thunderbolt a adaptéru pro PCI Express card.

Tyto adaptéry pak mohou být propojeny externě mimo skříň počítače v konfiguraci „daisy chain“, výsledné zařízení proto může být připojeno pouze jedním kabelem.
Prototyp GNSS přijímače
Pro konstrukci prototypu přijímače by bylo vhodné realizovat kompletně nový návrh celého přijímače včetně výpočetní jednotky, která by měla být založena na architektuře ARM s těmito požadavky:
- GPU podporující OpenCL (Výhodné pro výpočet akvizice)
- MCU s PCIe rozhraním (Vhodné pro komunikaci mezi FPGA a MCU)
Zatím bohužel ale takový ARM MCU není dostupný. Nejvhodnější vývojová deska tohoto typu je zatím ODROID-XU, která sice obsahuje GPU s podporou OpenCL. Avšak nemá PCI Express. Jedinné vysokorychlosní rozhraní je USB 3.0
Úkoly k vyřešení
- Dokončení návrhu potřebných modulů
- Výběr vhodné výpočetní jednotky pro realizaci prototypu
- Rozhodnutí o nutnosti, nebo zbytečnosti použití RTOS systému (na základě experimentů s testovacím přípravkem)
- Provedení otestování navrženého řešení
Prezentace
Reference
- The Witch Navigator - projekt open source GNSS přijímače FEL ČVUT.